共计 1654 个字符,预计需要花费 5 分钟才能阅读完成。
经常听到开发者问,百度蜘蛛是什么?最近百度蜘蛛来的太频繁服务器抓爆了!最近百度蜘蛛都不来了怎么办?还有很多站点想得到百度蜘蛛的 IP 段,想把 IP 加入白名单,但 IP 地址范围动态变化不固定,我们无法对外公布。
那么如何才能识别正确的百度蜘蛛呢? 今日干货带你轻松两步正确识别百度蜘蛛:
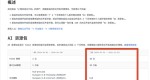
一、查看 UA 信息
如果 UA 信息不对,可以直接判断为非百度搜索的蜘蛛。目前 UA 分为移动、PC、和小程序三个应用场景,这三个渠道 UA 分别如下:
移动 UA:
Mozilla/5.0(Linux;u; 安卓 4.2.2;zh-cn;AppleWebKit/534.46(KHTML,like Gecko)版本 /5.1 Mobile Safari/10600.6.3(兼容; 百度钉 /2.0;+http://www.baidu.com/search/spider.html)
或
Mozilla/5.0(iPhone;CPU iPhone OS 9_1 与 Mac OS X 一样)AppleWebKit/601.1.46(KHTML,与 Gecko 一样)版本 /9.0 Mobile/13B143 Safari/601.1(兼容;Baiduspider-render/2.0;+http://www.baidu.com/search/spider.html)
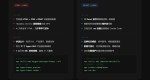
PC UA:
Mozilla/5.0(兼容; 百度蜘蛛 /2.0;+http://www.baidu.com/search/spider.html)
或
Mozilla/5.0(兼容; 百度蜘蛛渲染 /2.0;+http://www.baidu.com/search/spider.html)
小程序 UA:
Mozilla/5.0(iPhone;CPU iPhone OS 9_1 与 Mac OS X 一样)AppleWebKit/601.1.46(KHTML,与 Gecko 一样)版本 /9.0 Mobile/13B143 Safari/601.1(兼容; 百度蜘蛛渲染 /2.0; 智能应用程序;+http://www.baidu.com/search/spider.html)
二、双向 DNS 解析认证
第一步 >DNS 反查 IP
开发者通过对日志中访问服务器的 IP 地址运行反向 DNS 查找,判断某只 spider 是否来自百度搜索引擎,Baiduspider 的 hostname 以 *.baidu.com 或 *.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。
根据平台不同验证方法不同,如 linux/windows/os 三种平台下的验证方法分别如下:
1). 在 linux 平台下,您可以使用 host ip 命令反解 ip 来判断是否来自 Baiduspider 的抓取。
2). 在 windows 平台或者 IBM OS/ 2 平台下,您可以使用 nslookup ip 命令反解 ip 来 判断是否来自 Baiduspider 的抓取。打开命令处理器 输入 nslookup xxx.xxx.xxx.xxx(IP 地址)就能解析 ip,来判断是否来自 Baiduspider 的抓取。
3). 在 macos 平台下,您可以使用 dig 命令反解 ip 来判断是否来自 Baiduspider 的抓取。打开命令处理器输入 dig -x xxx.xxx.xxx.xxx(IP 地址)就能解析 ip,来判断是否来自 Baiduspider 的抓取。
第二步:对域名运行正向 DNS 查找
对第一步中通过命令检索到的域名运行正向 DNS 查找,验证该域名与您日志中访问服务器的原始 IP 地址是否一致,IP 地址一致可确认 spider 来自百度搜索引擎,IP 地址不一致即为冒充。
示例 1:
> 主机 111.206.198.69
69.198.206.111. in-addr.arpa 域名指针 baiduspider-111-206-198-69.crawl.baidu.com。
> 主机 baiduspider-111-206-198-69.crawl.baidu.com
baiduspider-111-206-198-69.crawl.baidu.com 地址为 111.206.198.69